GCSFS Adaptive Concurrent Prefetching: Architecture & Usage Guide
This feature is entirely experimental! To activate, you need to pass the environment variable USE_EXPERIMENTAL_ADAPTIVE_PREFETCHING=’true’ and DEFAULT_GCSFS_CONCURRENCY`=4. As currently written, this implementation is separate from the fsspec-style caching layer, but the intent is to eventually make this available to all asynchronous filesystems using the standard `cache_type= argument. How it interacts with the existing cache types (“readahead”, “first”, etc.) remains to be decided, and in the meantime, use at your own risk. We intend to develop more sophisticated caching strategies, perhaps specialised to file types.
Additional caveats: - the bytes slicing/copying code uses low level (ctypes) calls and offloads to a dedicated thread for performance. We intend to upstream some version of this to CPython, either in the slicing of bytes.join() code, but in the meantime we are using this ad-hoc implementation. More work on zero-copy methods on bytes buffers is expected. - the concurrent fetching code in _cat_file_concurrent is expected to be eventually upstreamed to the google SDKs, since low-level connection management should be the concern of the communication layer.
Introduction to Prefetching in GCSFS
When reading large files from cloud storage, the biggest bottleneck is network latency. If a program reads a chunk of a file, processes it, and then asks for the next chunk, the application spends most of its time idle, waiting for data packets to travel across the internet.
Prefetching solves this by predicting what data the application will need next and downloading it in the background before the application actually asks for it. By overlapping computation with network I/O, we can keep the application fed with data and significantly reduce total execution time.
Alongside this new prefetching architecture, native concurrency support for reads is now part of gcsfs. Previously, file reads were largely sequential. Now, gcsfs can download, or stream a file concurrently reducing the read time.
Inspiration & Architectural Adaptations
The core concept of this implementation is inspired by the Linux kernel’s file system prefetching algorithm (mm/readahead.c). Like the kernel, our system establishes a sliding window of data ahead of the user’s current read position and utilizes asynchronous pipelining fetching tomorrow’s data while the application processes today’s to hide I/O latency.
However, a cloud object store operates in a fundamentally different physical environment than a local NVMe drive. We made some architectural changes to adapt the kernel’s philosophy for Google Cloud Storage:
Base Operational Unit: The Linux kernel is fundamentally tied to the hardware’s virtual memory system, operating on tiny, fixed 4KB pages. In contrast, cloud read workloads (like pandas or Parquet) request data in massive, variable sizes. Instead of operating on a fixed 4KB hardware constraint, our prefetcher treats the user’s actual requested byte size (the “I/O Size,” which could be 100MB) as the fundamental block size for all background operations. We implemented a
RunningAverageTrackerthat continuously monitors the size of the user’s recent read requests and dynamically scales the prefetch window to match their actual behavior.Trigger Mechanisms: Because the kernel operates on small chunks, it can afford to wait. It can comfortably let the application consume several 64KB chunks before asynchronously triggering the next fetch, because reading those few chunks takes microseconds. However, because our base block size is massive, we cannot afford to wait. Waiting for multiple 100MB chunks to process before initiating the next network call would stall the application waiting on TCP/TLS handshakes. Therefore, we trigger prefetching immediately upon the consumption of the first block. As soon as the consumer pulls that first block, the background producer evaluates the buffer and proactively pushes the next chunk requests to ensure the pipeline never runs dry.
Scaling Strategy (Linear vs. Exponential): The Linux kernel typically ramps its prefetch window by aggressively doubling it (e.g., 2x, 4x). While this works flawlessly for local NVMe hardware where fetching from disk is incredibly fast and the penalty for over-fetching is practically zero, we explicitly abandoned exponential doubling for the cloud. In cloud object storage, fetching data across the internet is inherently slow, and network bandwidth is finite and expensive. If an exponential strategy blindly doubles a massive 50MB base request and pulls 100MB of unused data across the network before the application halts, that waste isn’t just discarded RAM, it is wasted API calls, inflated cloud egress costs, and consumed network bandwidth. Furthermore, dedicating maximum HTTP concurrency to aggressively download unproven data turns the prefetcher into a “noisy neighbor,” saturating the network interface and starving the core application of bandwidth it might need for other critical operations. To strictly control both fetch costs and network noise, our system scales linearly using a simple multiplier (
sequential_streak * io_size). This provides exactly enough background concurrency to effectively hide network latency without recklessly queuing up massive, expensive network requests that might ultimately be thrown away.Network Multiplexing vs. Hardware Queues: The Linux kernel breaks a readahead window into physical memory pages (e.g., 4KB) and pushes them down to the block layer, ultimately relying on the physical hardware controller’s queues (like NVMe multi-queue) to execute the I/O in parallel. In the cloud, there is no hardware controller to manage our parallelism, and a single HTTP stream is heavily bandwidth-capped. To saturate the network, the prefetcher must manufacture its own parallelism in software. Our
PrefetchProducerdynamically calculates asplit_factorto multiplex the prefetch window into several concurrent HTTP Range requests. By orchestrating these independent network streams directly within the Pythonasyncioevent loop, the prefetcher actively brute-forces the bandwidth ceiling that would otherwise choke a single HTTP connection.
How the Prefetching Components Work
Here’s how the prefetching works:
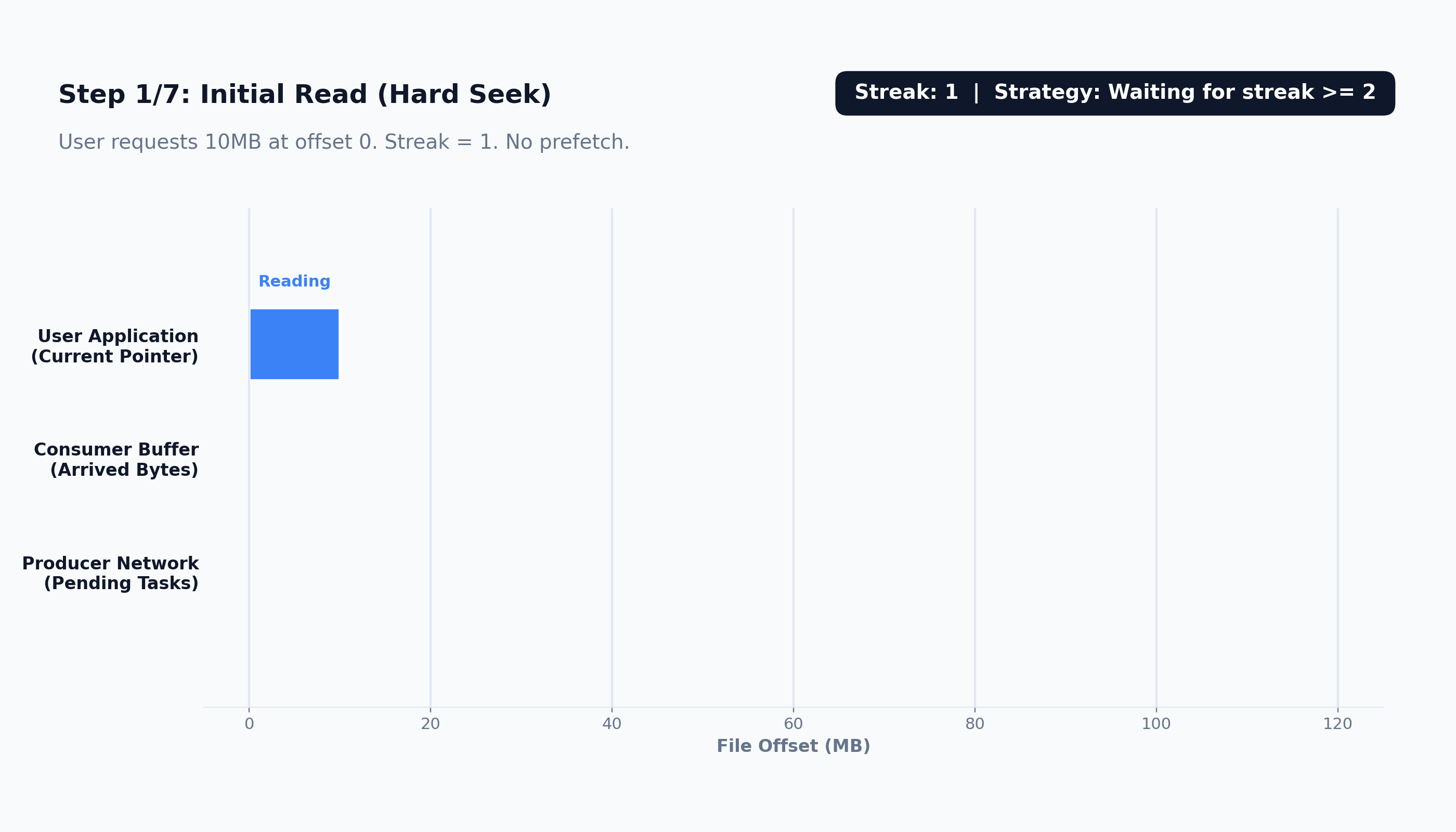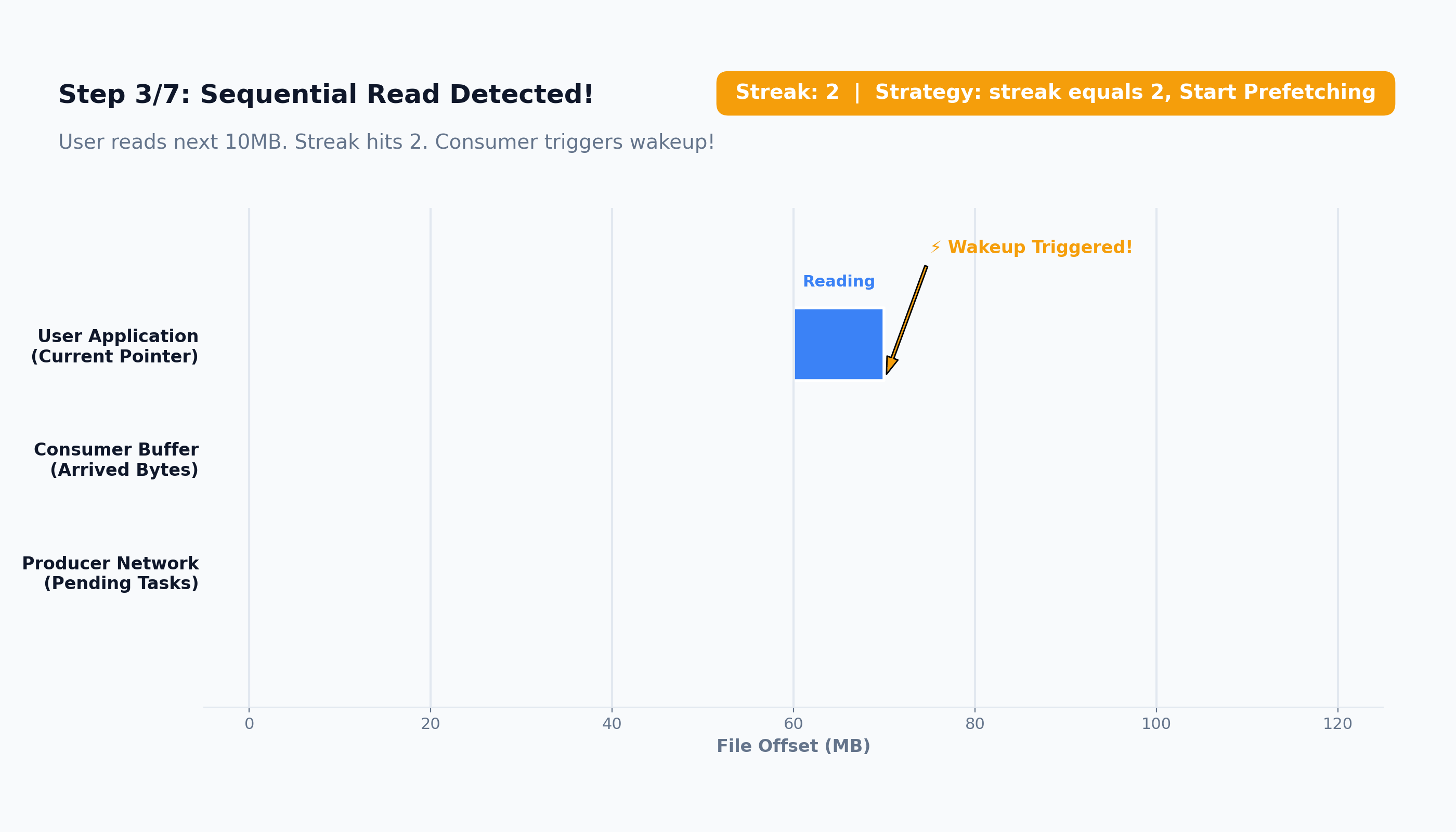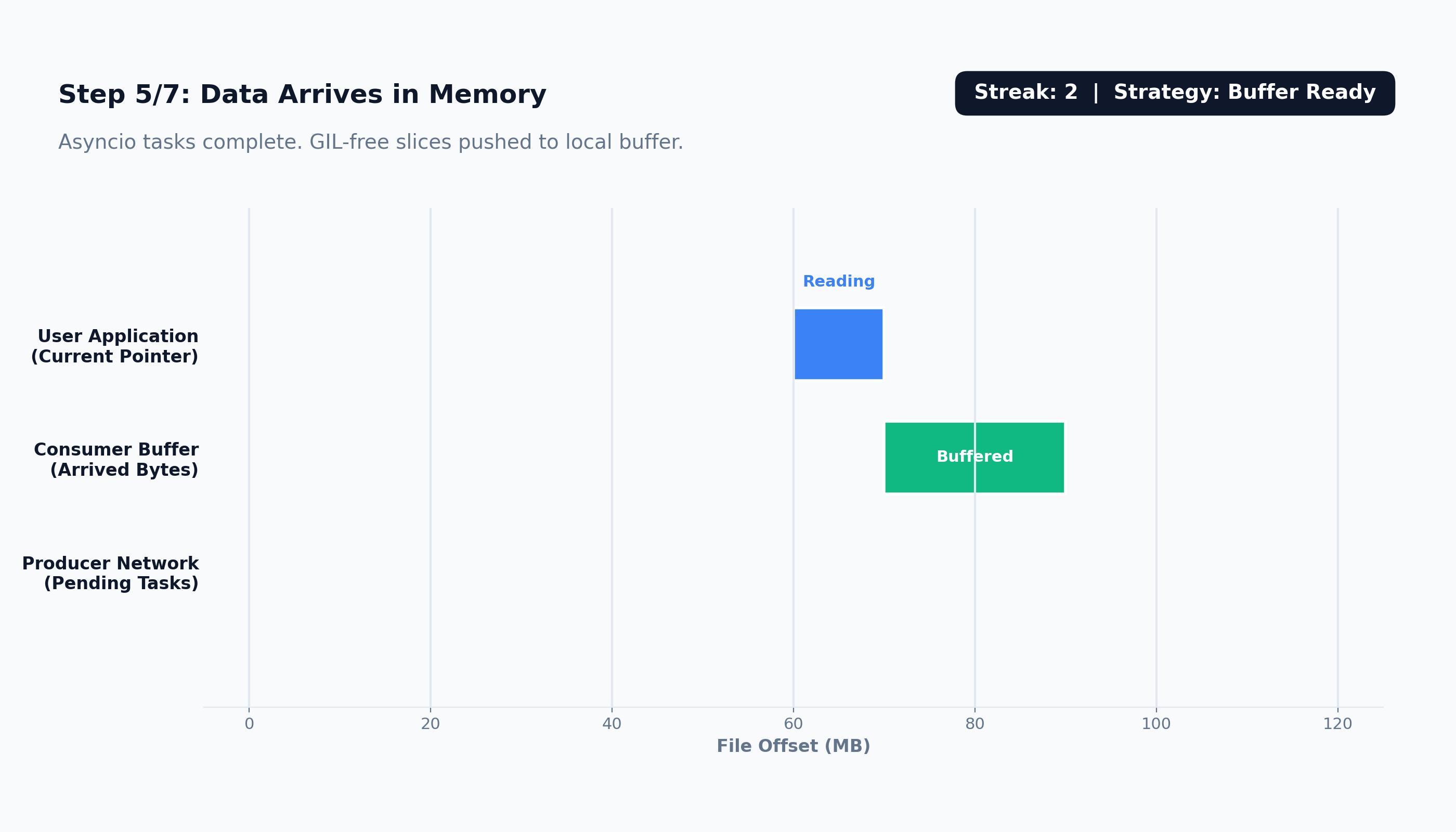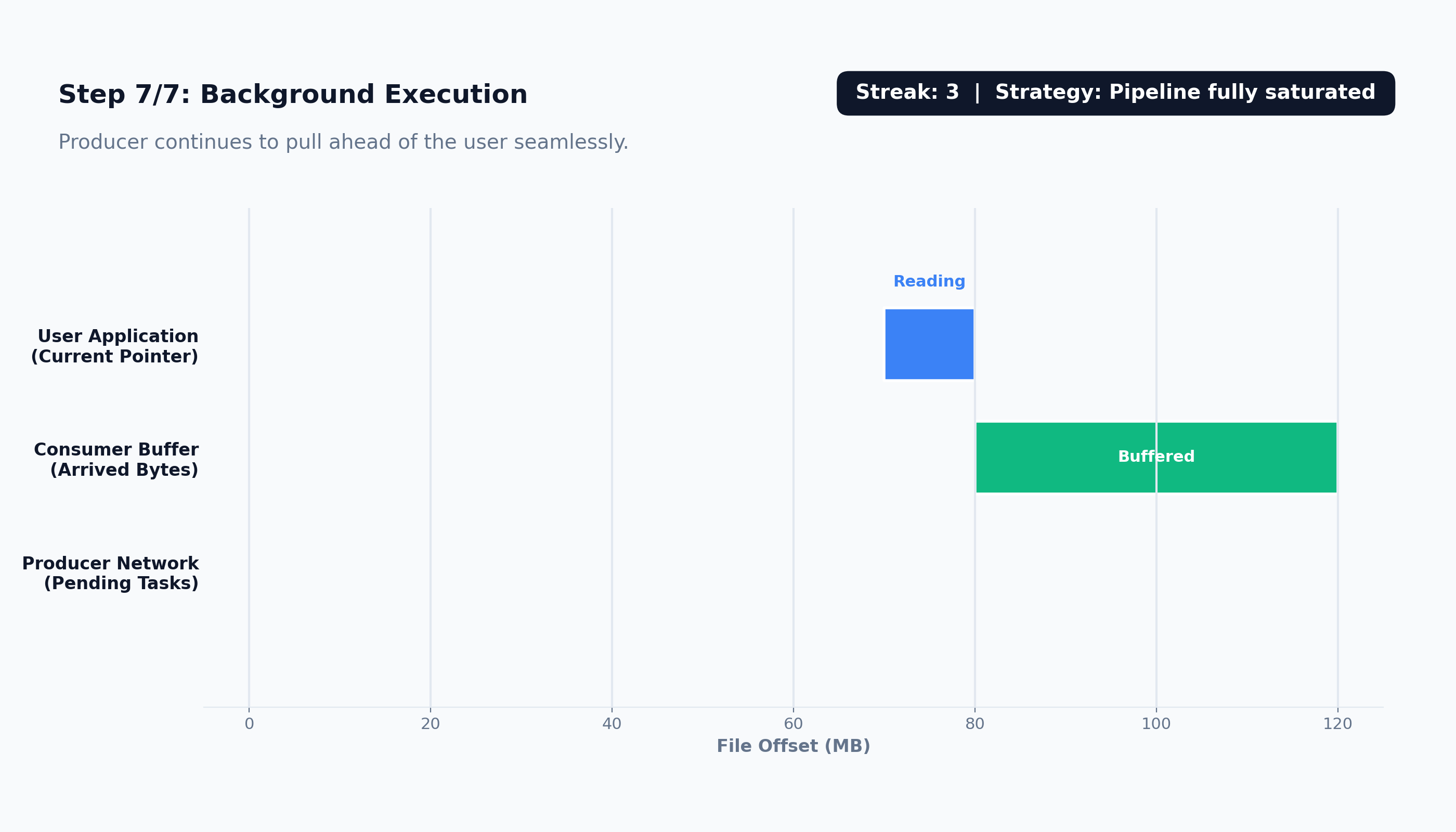
The prefetching system is broken down into four distinct, decoupled components.
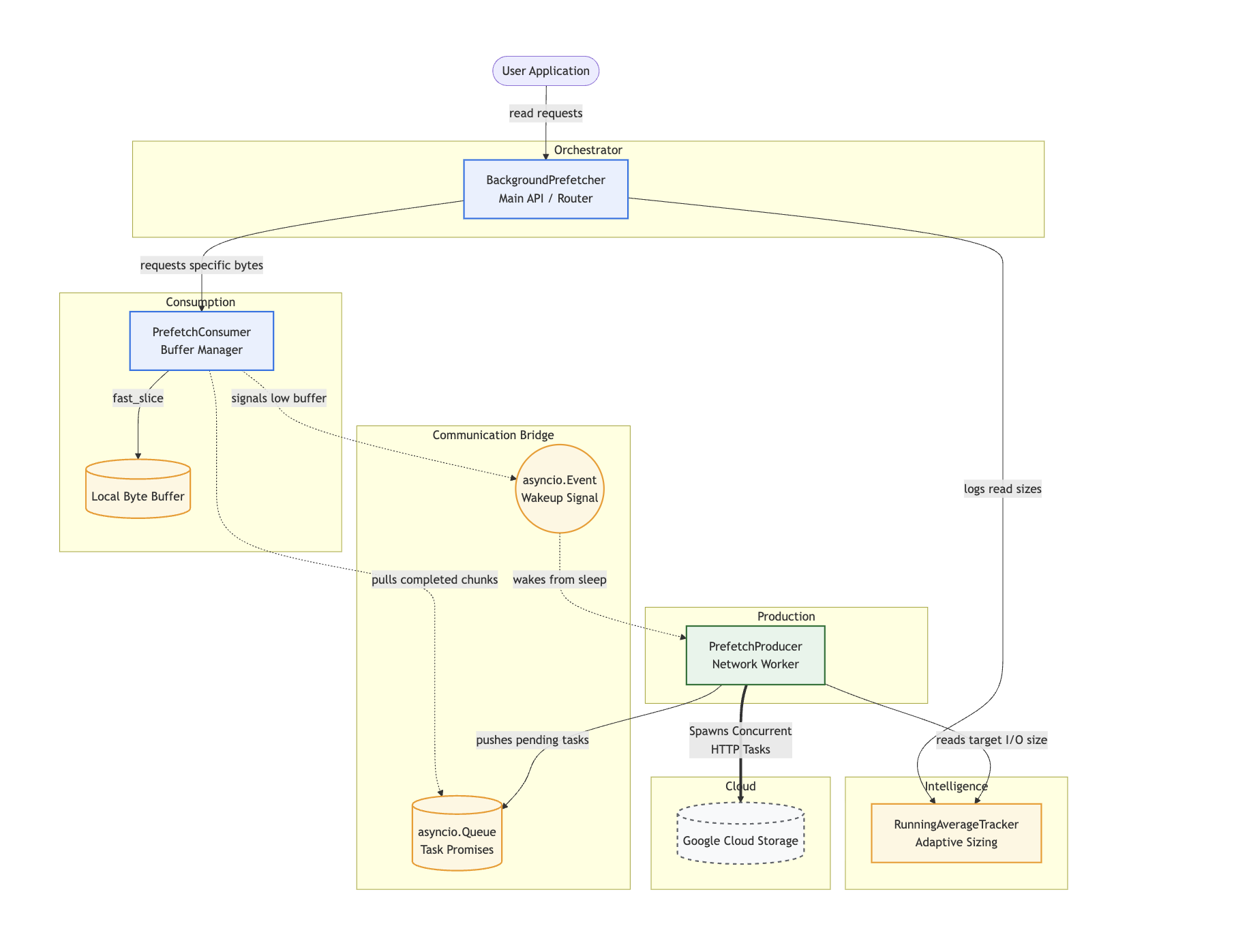
API Class Summary
``RunningAverageTracker``: Monitors the byte sizes of the user’s recent read requests. It calculates a rolling average to dynamically define the base I/O size, ensuring the engine scales to the current workload.
``PrefetchProducer``: A background asyncio task that dictates network strategy. It calculates the
prefetch_sizeand multiplexes the network stream by pushing concurrent download promises into a shared queue.``PrefetchConsumer``: Lives near the user application. It consumes background tasks from the queue, assembles the byte strings, and slices the exact data requested by the user while managing the local memory buffer.
``BackgroundPrefetcher``: The main public orchestrator. It ties the producer and consumer together, routes file seek operations (managing soft vs. hard seeks), and ensures active network sockets and memory buffers are cleanly flushed upon closing.
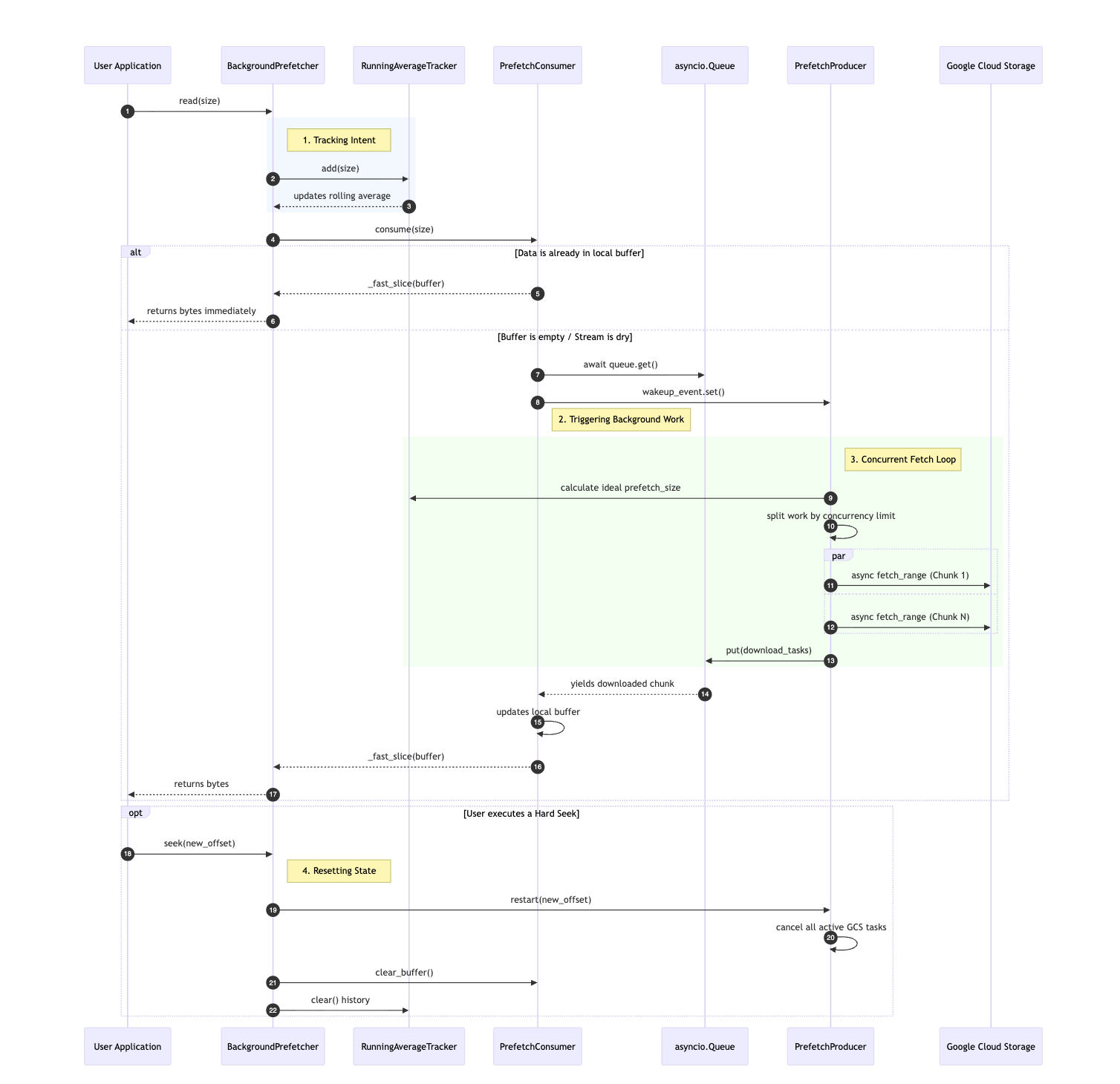
Interaction with GCSFile
The prefetcher is integrated into the GCSFile and replaces the standard sequential fetching mechanism when enabled.
Enabling the Feature
To use this architecture, set the following environment variables:
export DEFAULT_GCSFS_CONCURRENCY=4
export USE_EXPERIMENTAL_ADAPTIVE_PREFETCHING='true'
We recommend setting cache_type="none" for optimal results. The engine avoids prefetching for random workloads, and other cache types create unnecessary memory copies that degrade performance.
Under the Hood Lifecycle
During
GCSFile.__init__, if the feature is enabled, aBackgroundPrefetcheris instantiated and attached toself._prefetch_engine.GCSFile._async_fetch_rangeis mapped directly to the prefetcher.When
file.read(size)is called, it delegates toself._prefetch_engine._fetch(start, end).The prefetcher returns requested bytes from its local queue while the producer continues pulling chunks from GCS.
Calling
file.close()triggers_prefetch_engine.close(), safely canceling pending network tasks and clearing memory buffers to prevent memory leaks.
Standard Buckets Benchmarking with No Cache
Single Stream Performance (1 Process)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
114.87 |
231.31 |
0.81 |
seq |
1.00 |
440.73 |
391.49 |
0.82 |
seq |
16.00 |
448.21 |
427.76 |
0.80 |
seq |
100.00 |
320.67 |
788.53 |
0.82 |
rand |
0.06 |
0.60 |
379.40 |
0.66 |
rand |
1.00 |
9.16 |
372.26 |
0.85 |
rand |
16.00 |
89.60 |
373.14 |
0.73 |
rand |
100.00 |
220.53 |
616.53 |
1.03 |
Multi Stream Performance (16 Processes)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
2496.82 |
6455.58 |
9.29 |
seq |
1.00 |
7020.90 |
8183.40 |
8.77 |
seq |
16.00 |
9137.28 |
8343.03 |
8.31 |
seq |
100.00 |
6012.67 |
11017.45 |
8.03 |
rand |
0.06 |
17.86 |
4716.27 |
2.51 |
rand |
1.00 |
240.95 |
4549.06 |
1.07 |
rand |
16.00 |
2691.20 |
5739.50 |
3.53 |
rand |
100.00 |
5089.73 |
9342.88 |
6.88 |
Standard Buckets Benchmarking with default Readahead Cache
Single Stream Performance (1 Process)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
697.49 |
3261.87 |
0.81 |
seq |
1.00 |
789.34 |
1265.04 |
0.96 |
seq |
16.00 |
670.83 |
1264.07 |
0.99 |
seq |
100.00 |
293.33 |
1587.50 |
0.94 |
rand |
0.06 |
0.88 |
1144.77 |
0.59 |
rand |
1.00 |
13.51 |
1020.96 |
0.96 |
rand |
16.00 |
124.80 |
1040.35 |
1.00 |
rand |
100.00 |
237.07 |
1366.97 |
0.78 |
Multi Stream Performance (16 Processes)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
9335.52 |
6068.46 |
8.78 |
seq |
1.00 |
9285.69 |
6138.80 |
8.78 |
seq |
16.00 |
8092.48 |
6879.67 |
9.00 |
seq |
100.00 |
4212.00 |
11437.84 |
8.05 |
rand |
0.06 |
18.64 |
3209.76 |
2.75 |
rand |
1.00 |
266.63 |
3090.27 |
4.05 |
rand |
16.00 |
2730.56 |
4814.93 |
5.33 |
rand |
100.00 |
4182.53 |
9574.23 |
7.04 |
Rapid Buckets Benchmarking with default ReadAhead cache
Single Stream Performance (1 Process)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
709.47 |
3898.87 |
0.92 |
seq |
1.00 |
1063.34 |
1910.32 |
0.97 |
seq |
16.00 |
1348.37 |
2019.41 |
1.24 |
seq |
100.00 |
746.67 |
2700.23 |
1.21 |
rand |
0.06 |
5.84 |
2289.79 |
0.55 |
rand |
1.00 |
64.93 |
2179.14 |
0.49 |
rand |
16.00 |
623.79 |
2253.23 |
0.75 |
rand |
100.00 |
1335.33 |
2558.62 |
1.41 |
Multi Stream Performance (16 Processes)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
10416.80 |
14869.36 |
17.74 |
seq |
1.00 |
11215.91 |
14282.21 |
18.20 |
seq |
16.00 |
12532.69 |
17202.97 |
21.18 |
seq |
100.00 |
8447.33 |
25354.48 |
19.58 |
rand |
0.06 |
87.49 |
8445.38 |
8.55 |
rand |
1.00 |
1143.84 |
8316.45 |
7.83 |
rand |
16.00 |
8256.43 |
10901.46 |
13.04 |
rand |
100.00 |
14483.47 |
13797.95 |
24.56 |
Rapid Buckets Benchmarking with none cache_type
Single Stream Performance (1 Process)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
338.32 |
418.56 |
0.85 |
seq |
1.00 |
1256.67 |
493.22 |
1.18 |
seq |
16.00 |
2058.56 |
762.40 |
1.42 |
seq |
100.00 |
2007.20 |
989.16 |
1.77 |
rand |
0.06 |
42.83 |
698.52 |
0.59 |
rand |
1.00 |
268.29 |
627.70 |
1.12 |
rand |
16.00 |
1126.29 |
697.20 |
1.39 |
rand |
100.00 |
1786.80 |
870.89 |
1.56 |
Multi Stream Performance (16 Processes)
Pattern |
IO Size (MiB) |
Throughput (MiB/s) |
Max Mem (MiB) |
Max CPU (%) |
|---|---|---|---|---|
seq |
0.06 |
4417.29 |
8670.70 |
11.90 |
seq |
1.00 |
14176.76 |
9095.18 |
19.01 |
seq |
16.00 |
19369.49 |
13485.31 |
26.84 |
seq |
100.00 |
17205.33 |
14212.22 |
30.12 |
rand |
0.06 |
644.09 |
4435.87 |
3.92 |
rand |
1.00 |
2904.06 |
4562.50 |
5.33 |
rand |
16.00 |
13465.60 |
8496.34 |
14.47 |
rand |
100.00 |
16107.60 |
10651.09 |
27.58 |
Seeing the Prefetcher in Action
Real-world applications rarely do just one thing; they often switch between entirely different reading patterns mid-file. To understand how the engine balances aggressive fetching with careful memory management, we can look at a dynamic workload transition.
The graph below plots the size of the data requested by the application (User Read Size) against the volume of data the prefetcher is fetching in the background (Scheduled/Queued Data).
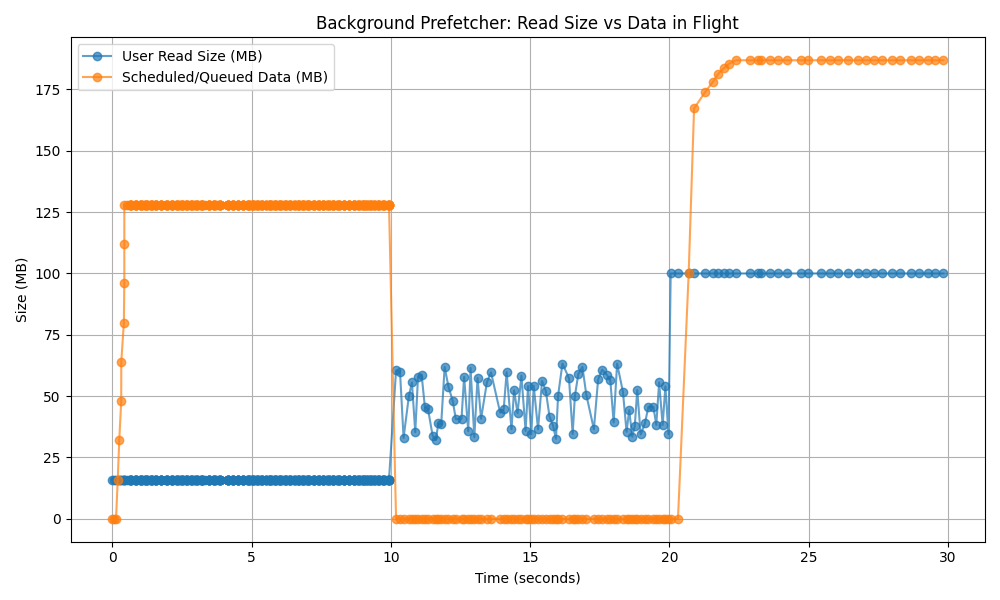
Notice how the prefetcher mirrors the application’s behaviour across three distinct phases:
Sequential reading (0–10s): The application starts by reading 16MB chunks. After three reads, the prefetcher ramps up its background fetching. It maintains a buffer ahead of the application so the user never waits on the network.
Random seeks (10–20s): The application starts jumping randomly around the file. Prefetching would be harmful here. The engine detects the broken streak and drops the background buffer to zero, ensuring no network bandwidth or memory is wasted downloading data.
Larger sequential reads (20–30s): The application resumes reading sequentially, but this time stepping up to 100MB chunks. The algorithm detects the new streak, calculates the new rolling average, and rebuilds the background buffer—this time scaling it up to handle the larger data chunks.